
Currently Empty: £0.00

aptLearn
Understanding Machine Learning and Its Applications

Machine Learning is a subset of artificial intelligence (AI) that provides systems with the ability to automatically learn and improve from experience without being explicitly programmed. It focuses on the development of computer programs that can access data and use it to learn for themselves.
The process of learning begins with observations or data, such as examples, direct experience, or instruction, to look for patterns in data and make better decisions in the future based on the examples that we provide. The primary aim is to allow computers to learn automatically without human intervention or assistance and adjust actions accordingly.
Understanding the Workflow of Machine Learning Algorithms
Machine learning algorithms are the backbone of artificial intelligence technologies, and they function by following a systematic workflow. This workflow is a series of steps that guide the process from data collection to making predictions. Let’s delve into each of these steps:
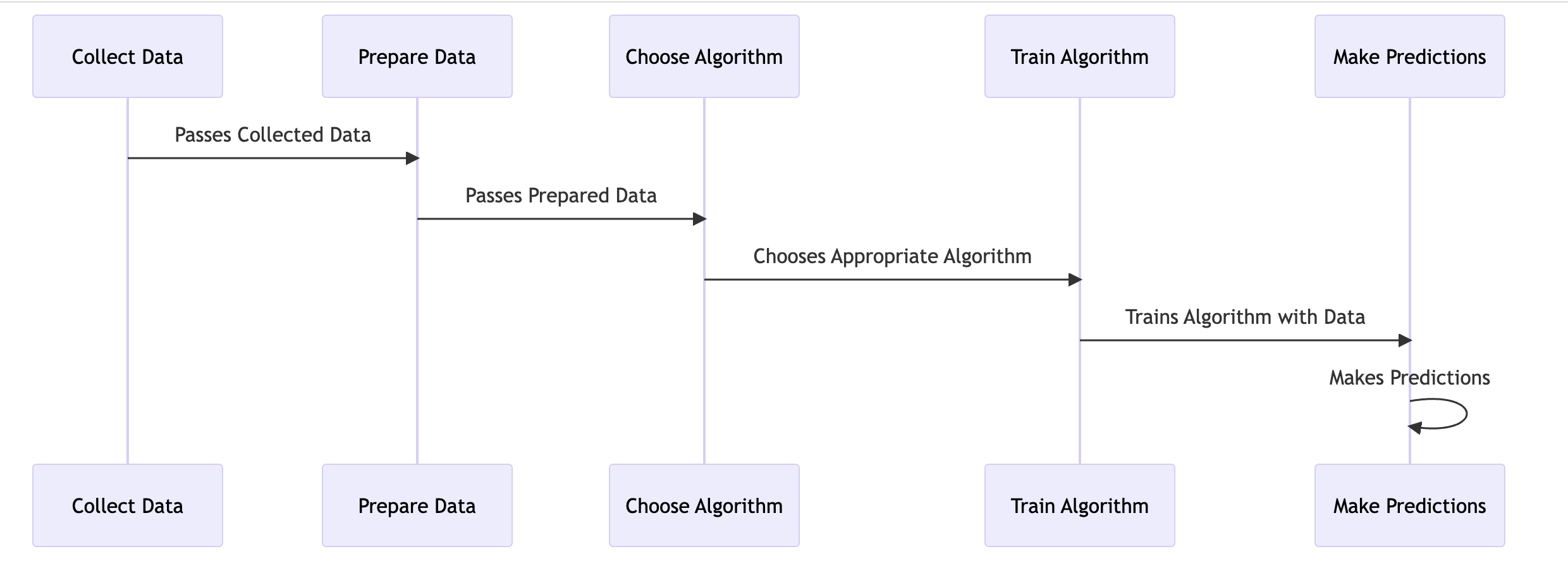
Collecting Data
Data is the lifeblood of machine learning. The type and amount of data you collect will directly influence the performance of your machine-learning model. Data can come from a variety of sources, including databases, files, APIs, web scraping, and even real-time sensors. The key is to collect data that is relevant to the problem you’re trying to solve.
For instance, if you’re building a machine learning model to predict house prices, you might collect data on the size of the house, the number of rooms, the location, the age of the house, and so on. This data can be collected from real estate websites, government databases, or other relevant sources.
Preparing the Data
Once you’ve collected your data, it needs to be prepared or preprocessed before it can be used in a machine-learning model. This can involve a variety of processes, including:
- Cleaning the data: This involves removing or correcting erroneous data, filling in missing values, and dealing with outliers.
- Transforming the data: This might involve scaling numeric data, encoding categorical data (converting categories into numbers), or extracting features from the data.
- Splitting the data: It’s common practice to split your data into a training set (used to train the model) and a test set (used to evaluate the model).
Choosing an Algorithm
The choice of algorithm depends on the problem you’re trying to solve and the nature of your data. For instance, if you’re working on a classification problem (predicting discrete categories), you might choose an algorithm like logistic regression or a decision tree. If you’re working on a regression problem (predicting continuous values), you might choose linear regression or a support vector machine.
Training the Algorithm
Training the algorithm involves feeding it your prepared data and allowing it to learn from it. This is where the algorithm identifies patterns in the data and builds a mathematical model that fits the data. The specifics of this process will depend on the algorithm you’re using.
Making Predictions
Once the algorithm has been trained, it can be used to make predictions on new, unseen data. You simply input your new data into the model, and it outputs a prediction based on what it has learned from the training data.
In the next section, we will discuss some of the common challenges and best practices in machine learning.
There are three types of Machine Learning algorithms:
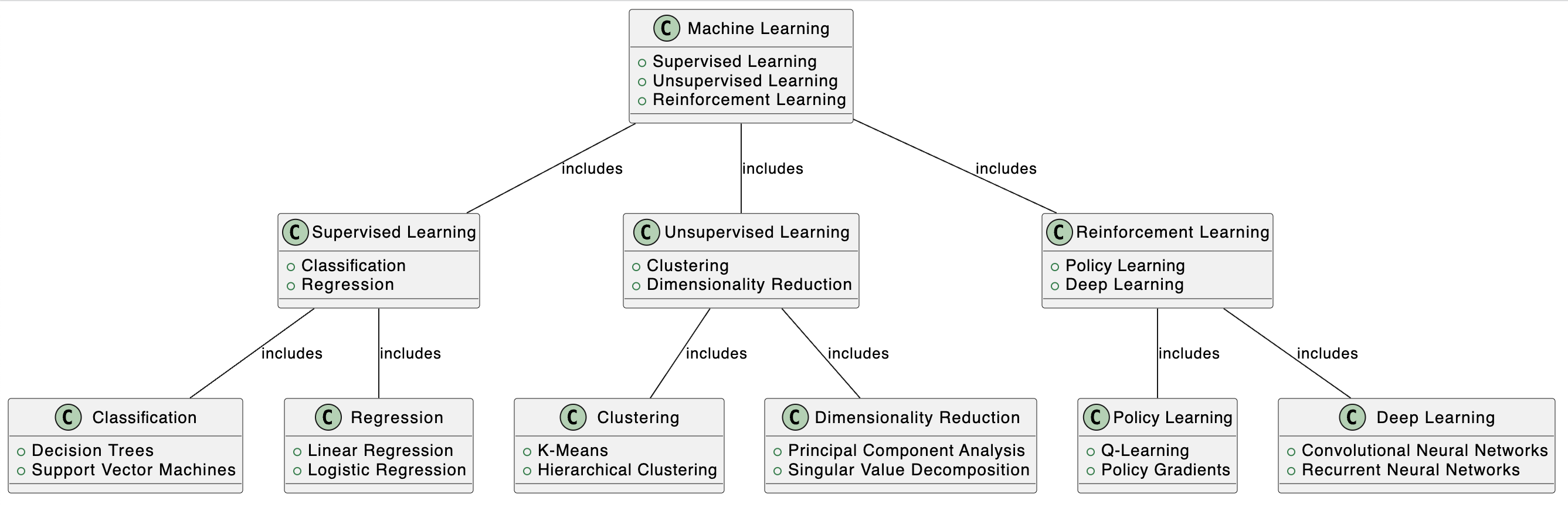
- Supervised Learning: In this type of learning, the model is trained on a labelled dataset. The labelled dataset is one where the target variable is known. There are two types of Supervised Learning techniques: Classification and Regression.
- Classification: It involves predicting the class of the given data points. Examples of classification problems are Image classification, Speech Recognition, and Identifying cancer in health datasets. Some common classification algorithms include Decision Trees and Support Vector Machines.
- Regression: It involves predicting a continuous-valued output. Examples are predicting stock prices, predicting house prices, customer lifetime value prediction. Some common regression algorithms include Linear Regression and Logistic Regression.
- Unsupervised Learning: In this type of learning, the model is trained on an unlabelled dataset and allows the algorithm to act on that information without guidance. There are two types of Unsupervised Learning techniques: Clustering and Dimensionality Reduction.
- Clustering: It involves grouping data points of similar type into one group. Examples are customer segmentation, organizing computing clusters, and social network analysis. Some common clustering algorithms include K-Means and Hierarchical Clustering.
- Dimensionality Reduction: It involves reducing the number of random variables under consideration, by obtaining a set of principal variables. Examples are Big data visualization, structure discovery, and meaningful compression. Some common dimensionality reduction algorithms include Principal Component Analysis and Singular Value Decomposition.
- Reinforcement Learning: It is a type of learning where an agent learns to behave in an environment, by performing certain actions and observing the results/results. There are two types of Reinforcement Learning techniques: Policy Learning and Deep Learning.
- Policy Learning: It involves the process of long-term goal planning. Examples are game AI, real-time decisions, and robot navigation. Some common policy learning algorithms include Q-Learning and Policy Gradients.
- Deep Learning: It involves making a computer model that mimics the human brain. It is used for tasks that involve artificial intelligence (AI). Examples are voice recognition for home automation systems, chatbots, and driverless cars. Some common deep learning algorithms include Convolutional Neural Networks and Recurrent Neural Networks.

ChatGPT as A Case Study
ChatGPT is a state-of-the-art language model developed by OpenAI. It’s powered by gpt-3.5-turbo, one of the most powerful language models available. ChatGPT has been trained on a diverse range of internet text, but it can also be fine-tuned with specific datasets for various tasks.
ChatGPT is an example of a machine learning application in the field of Natural Language Processing (NLP). It’s designed to generate human-like text based on the input it’s given. This makes it incredibly versatile, with potential applications ranging from drafting emails or writing code, to creating written content or tutoring in a variety of subjects.
The diagram below provides a simplified view of how a user’s prompt is processed by ChatGPT and a response is generated:
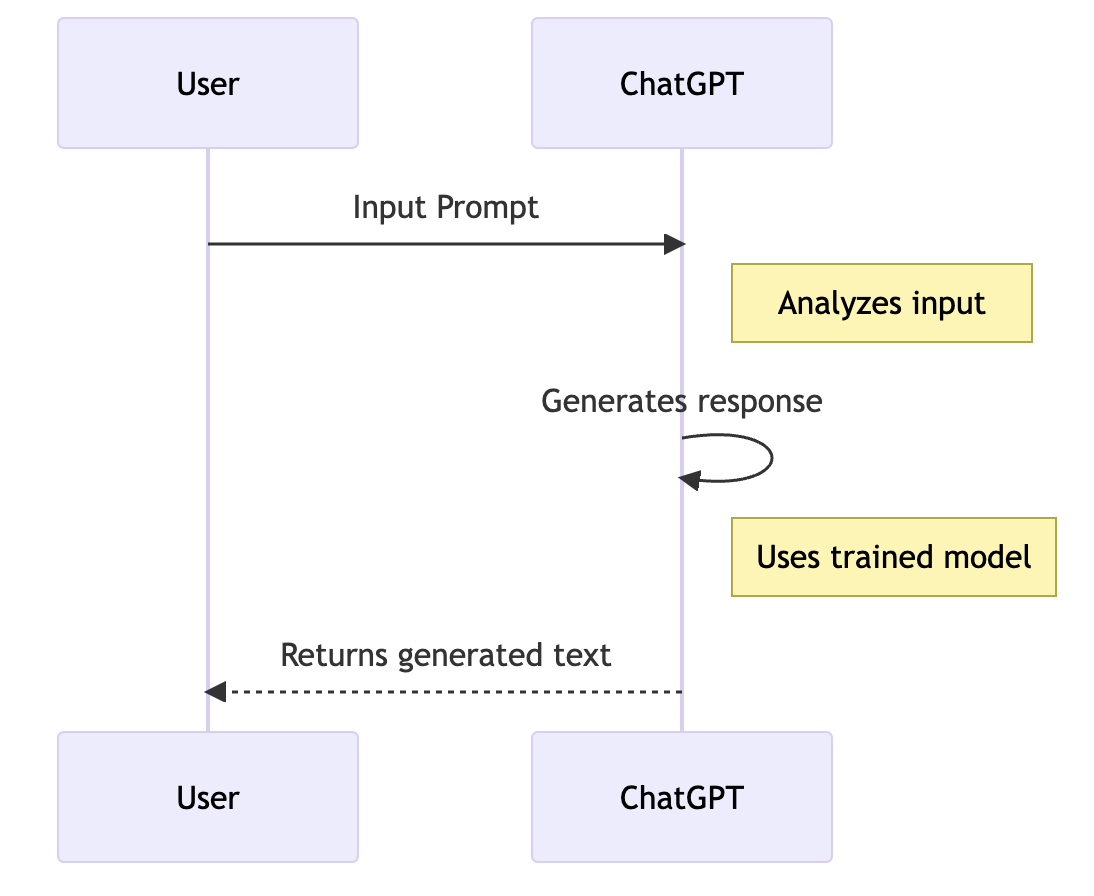
In the context of our discussion:
- Data Collection and Preparation: ChatGPT is trained on a diverse range of internet text. This data is collected and prepared for the training process, which involves cleaning the data and converting it into a format that the machine learning model can understand.
- Choice of Algorithm: The underlying algorithm for ChatGPT is a transformer-based model, specifically a variant of the GPT (Generative Pretrained Transformer) model. This model is particularly suited for understanding the context of natural language.
- Training the Algorithm: The prepared data is used to train the model. During this process, the model learns to understand the structure of human language, including grammar, context, and even some world facts.
- Making Predictions: Once the model is trained, it can generate text based on a given input. It does this by predicting what text should come next based on the input it’s given.
Remember, this is a simplified explanation. The actual process involves more complexity and various other components that ensure the efficient and accurate functioning of the model.
Future of Machine Learning
Machine learning is a rapidly evolving field, and its potential applications are only limited by our imagination. Let’s delve deeper into the future applications of machine learning that we discussed earlier.
Personalized Medicine
Machine learning can revolutionize the healthcare industry by providing treatments that are tailored to an individual’s unique genetic makeup and health history. This is known as personalized medicine. By analyzing a patient’s individual genetic and medical data, machine learning algorithms can predict how a patient will respond to a particular treatment. This can help doctors to choose the most effective treatment for each individual patient, improving outcomes and reducing side effects.
Smart Cities
Machine learning can also be used to improve the efficiency and sustainability of cities. This could involve optimizing traffic flow to reduce congestion, managing energy consumption to reduce waste, and even preventing crime by predicting where it is most likely to occur. For instance, machine learning algorithms can analyze traffic data in real time to predict where congestion is likely to occur and adjust traffic signals accordingly. This can help to reduce travel times and improve the efficiency of the transport network.
Artificial Intelligence
Machine learning is a key component of artificial intelligence (AI). As AI continues to develop, machine learning will become even more important. It will be used to improve the accuracy of AI predictions, make AI systems more efficient, and enable new AI capabilities. For example, machine learning algorithms can be used to analyze large amounts of data and identify patterns that humans might miss. This can help to improve the accuracy of AI predictions and enable new AI capabilities, such as the ability to understand natural language or recognize images.
Conclusion
Machine learning is a transformative technology that’s reshaping the world around us. From personalized medicine and smart cities to advanced AI like Google’s Bard and OpenAI’s ChatGPT, machine learning is at the heart of these innovations.
In our exploration of machine learning, we’ve seen how it works, its different types, and its myriad applications. We’ve delved into the world of natural language processing with ChatGPT, a model that can generate human-like text, and Google Bard, a chatbot that, despite its initial shortcomings, showcases the potential of AI in communication.
But this is just the tip of the iceberg. The future of machine learning holds even more promise. As technology continues to evolve, we can expect machine learning to become more integrated into our daily lives, making our interactions with technology more seamless and intuitive.
As we continue to explore and understand machine learning and its applications, one thing is clear: machine learning is not just a trend or a buzzword. It’s a powerful tool that’s here to stay, and its potential to transform our world is immense.
So, whether you’re a business looking to leverage machine learning for growth, a developer interested in building machine learning models, or a curious individual eager to understand the technology shaping our world, there’s no better time than now to dive into the fascinating world of machine learning. The journey may be complex, but the rewards are well worth it.